

Högre prestanda med adaptiv beräkningsacceleration
I vår ständigt uppkopplade och datacentrerade tid med AI överallt stiger efterfrågan på ökad bandbredd bortom dagens tekniker och formfaktorer. Det kräver mer effektiv och genomträngande bearbetning som skalar utöver vad nuvarande CPU- och GPU-teknik klarar.
Glöm pengar. Det är data som får världen att snurra. Allt handlar om att flytta, hantera och analysera data, från avlägsna IoT-slutpunkter som samlar in data för olika ändamål – stadsplanering, hälsospårning, miljöskydd, verksamhetsförbättring – till vår aptit på streaminginnehåll och att dela våra liv på nätet. Konsumenterna använder i allt högre utsträckning personliga IoT-enheter som alltid är anslutna, och affärsrelaterad och vetenskaplig forskning förlitar sig alltmer på AI-centrerade applikationer.
Den digitala livsstilen och det framväxande IoT är fast förknippade med den snabba tillväxten av bearbetning och datatjänster i molnet. Molnet står i centrum för nya sätt att leva och arbeta. Där lagras massiva mängder personligt innehåll för åtkomst i farten, där finns on-demand-tjänster för musik- och videostreaming, där samlas bransch- eller företagsdata in och analyseras och där görs kraftfulla programvaror tillgängliga kostnadseffektivt på en per-cykler-basis för sådant som ekonomisk analys, databassökning eller genomsekvensering.
Dessutom kommer 5G New radio (NR), som introducerar stöd för Massive Machine-Type Communications (MMTC) och kommunikation med extremt låg latens (ULLC) för att möjliggöra nya mobiltjänster i realtid, att sätta en intensiv press på kapaciteten och prestanda för anslutningsnät, stadsnät och kärnnätverk.
Ökat tryck på kärninfrastrukturen
Det finns en stor efterfrågan på ökad databandbredd och beräkningsgenomströmning i alla dagens molndatacenter och i telekomnätverk och cellulära anslutningsnät. Några viktiga komponenter är länkar till och från datacenter och datacentersammankopplingar (DCI) som kopplar samman geografiskt distribuerade datacenterplatser, infrastrukturgränssnittskort och acceleratorkort. Faktum är att efterfrågan på databandbredd i kärninfrastrukturen växer nominellt till 51 % CAGR och efterfrågan på områdestrafik kommer att öka hundrafaldigt enbart på grund av 5G-lanseringen.
Att bygga ny och bättre utrustning för att uppfylla dessa krav med diskreta komponenter som protokollhantering och gränssnittschip är inte bara komplicerat och tidskrävande, utan kan också i allt högre grad inte skalas efter prestandakrav. Design av det här slaget skapar dessutom stora och energikrävande system som inte kan tillgodose kraven på hantering av fastigheter, energiförbrukning och värme gällande datacenter- och infrastrukturutrustning. Utrustning av nästa generation måste ge betydligt bättre prestanda inom befintliga fysiska, elektriska och värmerelaterade gränser.
Dessutom måste man i designarbetet börja använda de senaste protokollen och standarderna innan man enas om de slutliga specifikationerna så att utrustningen kan vara marknadsredo så snart som möjligt. Utrustningsleverantörer som vill vara tidigt ute på marknaden kan inte vänta på att specifikationerna ska mogna. Därför är det nödvändigt att även vara flexibel på maskinvarunivå allteftersom projektet fortskrider.
Banbrytande programmerbar accelerator
Programmerbara logiska enheter såsom FPGA:er med hög densitet och programmerbara systemkretsar (MPSoC) har blivit förstahandsvalet för arbetsbelastningar som inte kan utföras tillräckligt snabbt i konventionella CPU- eller GPU-arkitekturer eller som inte uppfyller energikraven. De erbjuder en hög grad av parallellitet för att avlasta specifika beräkningssvårigheter på ett mycket effektivt sätt – till exempel signalbearbetning och, på senare tid, neurala nätverk – och ger även den inneboende anpassningsförmåga som programmerbara enheter innebär.
För att tillgodose de senare och mer krävande målen i fråga om prestanda, bandbredd, energi och integration har nu en ny klass av programmerbara enheter som kallas ACAP (Adaptive Compute Acceleration Platform) vuxit fram. Xilinx Versal ACAP innehåller en rad intelligenta AI- och DSP-beräkningsmotorer, anpassningsbara motorer som är likvärdiga med FPGA-logiksystemet och skalära motorer för applikationsbearbetning i realtid, som är nära förbundna genom en programmerbar NoC-sammankoppling (Network on Chip). Dessutom är programvarustyrd plattformshantering och toppmoderna gränssnitt, inklusive DDR4, 100G Ethernet, PCIe Gen 5 och optiska gränssnitt med flera gigabit integrerade.
Versal DSP-motorerna har förbättrade DSP-block med inbyggt stöd för operander som INT8, 32-bitars flyttal med flera, för att öka applikationernas hastighet och effektivitet. De omfattar inte bara digital signalbehandling utan även breda dynamiska bussväxlar, minnesadressgeneratorer, breda bussmultiplexer och minnesmappade I/O-register. De skalära motorerna består av applikationsprocessorn Arm Cortex-A72 med dubbla kärnor och realtidsprocessenheten Arm Cortex-R5F med dubbla kärnor. ACAP:s heterogena motorer kan omprogrammeras för att anpassa sig till arbetsbelastningar som förändras över tiden eller när algoritmiska implementeringar eller neurala nätverksmodeller utvecklas.
Optimera ACAP för anslutning
Versal Premium-serien bygger vidare på de innovationer som etablerats av den här nya klassen av programmerbara enheter och finns nu tillgänglig för att hantera trycket på dagens kärninfrastruktur. I dessa enheter med hög bandbredd kombineras hög beräkningsdensitet med ytterligare dedikerade kryptografiska motorer med hög hastighet (HSC) och toppmoderna nätverksgränssnitt.
Den intensiva nätverksanslutningen omfattar skalbara optiska sändtagare upp till dubbelriktad bandbredd med 9 Tbit/s som stöder de senaste Ethernet- och Interlaken-hastigheterna och -protokollen, PAM4-sändtagarna med 112 Gbit/s och kryptografisk bearbetning med krypteringsmotorer på upp till 400 Gbit/s och anpassningsbar maskinvara (figur 1).
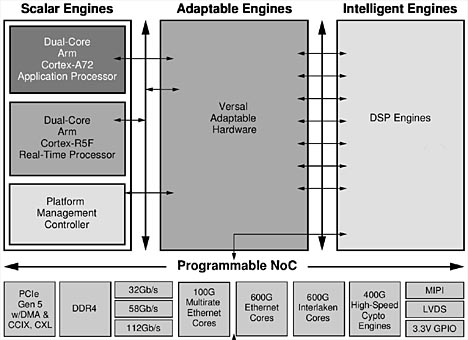
Fig 1. Versal Premium-ACAP med 112 Gbit/s PAM4, 600G Ethernet, 600G Interlaken och 400G HSC
Jämfört med befintlig PAM4-teknik med 58 Gbit/s kan en fördubbling av bandbreddsdensiteten per port minska trycket på frontpanelens rackutrymme med hjälp av 112G PAM4-sändtagare för grundläggande infrastruktur samt stads- och DCI-infrastruktur. Dessutom kan bandbredden per enhetsvolym i Telco- och datacenterapplikationer fördubblas. Samtidigt är latensen vid överföring av en viss datanyttolast 50 % lägre, vilket gör applikationerna mer responsiva och hjälper till att minska latenspåverkan vid sammankoppling av geografiskt distribuerade datacenter.
De resurser som är integrerade på chip ger upp till tre gånger så hög bandbredd och fördubblar beräkningsdensiteten hos 16nm Virtex UltraScale+-FPGA-enheter från Xilinx. Samtidigt är applikationernas genomströmningskapacitet tre till fem gånger högre än en dedikerad applikationsspecifik OTN-processor (Optical Transport Network).
Ökad beräkningsdensitet
För att möta de nuvarande och framtida kraven från storskaliga molntjänsteleverantörer kombinerar Versal ACAP-arkitekturen extremt hög minnesbandbredd på chip tätt kopplad till högpresterande heterogena beräkningsmotorer med flexibel arbetsbelastningsallokering genom Dynamic Function eXchange (DFX). Med möjligheten att byta kärnor åtta gånger snabbare än föregående 16nm FPGA-enheter gör DFX att dynamisk allokering av acceleratorer kan använda enhetsresurser så effektivt som möjligt för beräkningsbelastningar som förändras över tid. Det handlar bland annat om dataanalys, bearbetning av maskininlärningsvision, genomik, videoomkodning, kryptografisk bearbetning med mera.
Med flera olika typer av distribuerat RAM-minne på chip finns upp till 1 Gbit av tätt kopplat minne tillgängligt, med motsvarande chipminnesbandbredd på upp till 123 Tbyte/s. Detta möjliggör snabba interaktioner mellan olika bearbetningsmotorer och minne som är nio gånger snabbare än vad dagens bästa grafikprocessorer kan uppnå. Dessutom stödjer den programmerbara NoC-sammankopplingen snabb interaktion med DDR4-minne utanför chipet.
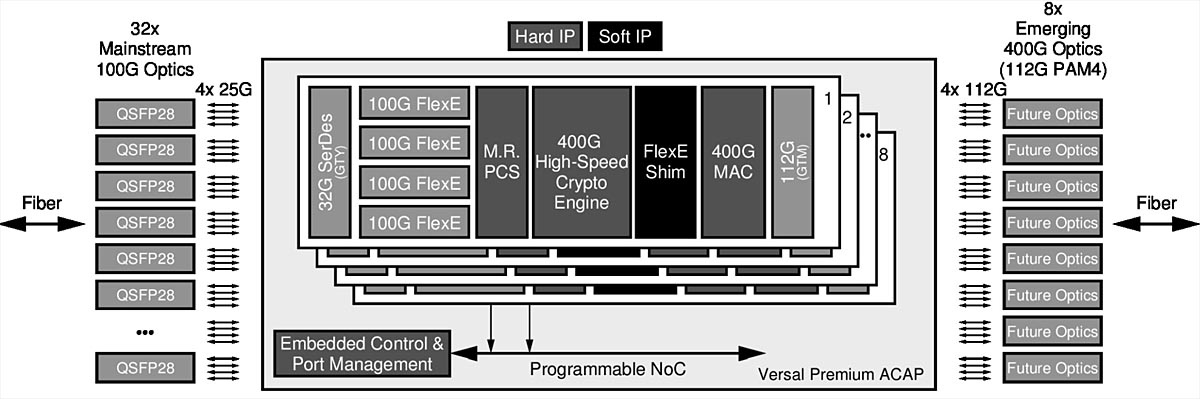
Versal Premium ACAP kan uppfylla kraven på DCI-utrustning att kunna hantera olika typer av optik och protokoll på server- och transportsidan samtidigt som de är fria att anpassa sig till framväxande standarder och standarder i utveckling på en säker och kostnadseffektiv plattform. Ett 1RU-system eller ett enda kort kan byggas för att ge kapacitet på 3,2 Tbit/s med stöd för en rad olika standardiserade och framväxande protokoll och optik (figur 2). En enda Versal Premium ACAP, med dess toppmoderna anslutningsmöjligheter och kryptografiska kärnor, kan implementera flera kanaler på 100G FlexE Ethernet med 4 x 25G NRZ-anslutningar till optik på serversidan, 400G Ethernet-kanaler på linjesidan som implementeras med 4 x 112G PAM4-anslutningar, AES256 kryptering med linjehastighet på 1,6 Tbit/s samt kontroll-och port hanteringsfunktioner.
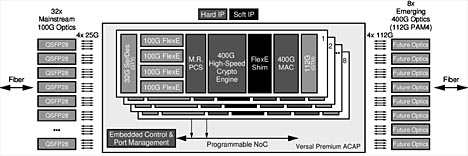
Figur 2. 3,2 Tbit/s DCI utnyttjar Versal Premium ACAP (klicka för större bild)
Enheterna passar även perfekt för klientgränssnittskort med höga hastigheter (figur 3) genom att utnyttja Versal Premium ACAP för att överbrygga och kapsla in digital trafik och tjänster i branschstandard OTN-omslag. De integrerade kanaliserade sändtagarna med Ethernet, Interlaken och 112G och 58G PAM4 GTM samt sändtagare med 32,75G GTYP ger kapacitet för flera terabit/s. Dessa resurser är integrerade som dedikerad hård-IP och möjliggör energieffektivitet i ASIC-klass samtidigt som ACAP-logiksystemet är fritt för mappnings-, omkostnads- och SAR-funktioner.
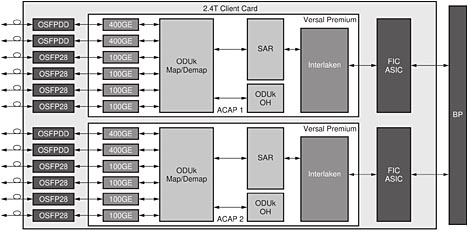
Figur 3. Klientgränssnittskort med 2,4 Tbit/s
Framtidssäker AI-acceleration
Genom kombinationen av heterogena beräkningsmotorer och hög minnesbandbredd kan Versal Premium ACAP ge en betydande prestandaförbättring jämfört med GPU:er vid hantering av tuffa arbetsbelastningar såsom bildklassificering eller objektdetektering med neurala nätverk. I figur 4 jämförs prestanda med ledande GPU:er, vilket visar hur objektdetektering som körs på en 680 x 680 YOLOv2-modell kan vara så mycket som 7,7 gånger snabbare på en ACAP Premium-enhet.
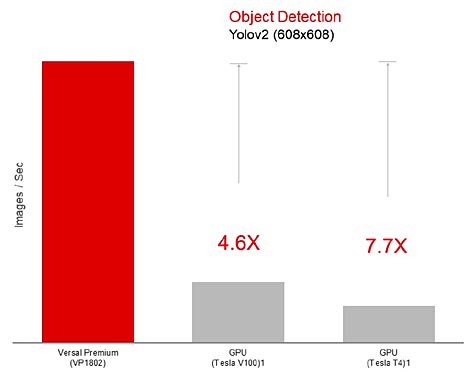
Figur 4. Prestanda för objektdetektering jämfört med GPU:er. (Nvidia Data Center Deep Learning Product Performance: https://developer.nvidia.com/deep-learning-performance-training-inference)
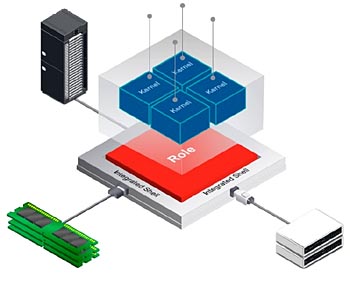
Ett annat intressant inslag i ACAP som förenklar acceleratorutveckling jämfört med FPGA- och MPSoC-arkitekturer är det färdiga skalet som ger hårda anslutningar till gränssnitt utan chip såsom Ethernet, PCIe Gen 5, DDR4 och optiska gränssnitt (figur 5). Den här effektiva infrastrukturen för molnanslutning ger flera fördelar, bland annat att den gör CPU-värd- och systemminneskommunikation tillgänglig när enheten startas och underlättar kärnplacering, tidsanpassar stängning och förenklar acceleratorvirtualisering. Med skalet kan designer använda mer av enhetens interna logiksystem för anpassade funktioner, vilket annars skulle krävas för att implementera nödvändig infrastruktur som minne och DMA-styrenheter.
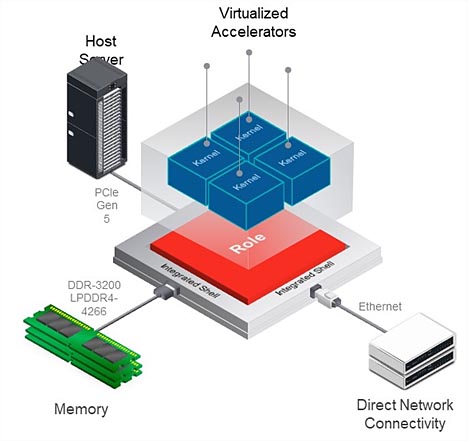
Figur 5. Färdig skalinfrastruktur förenklar molnanslutning och ökar hastigheten och effektiviteten
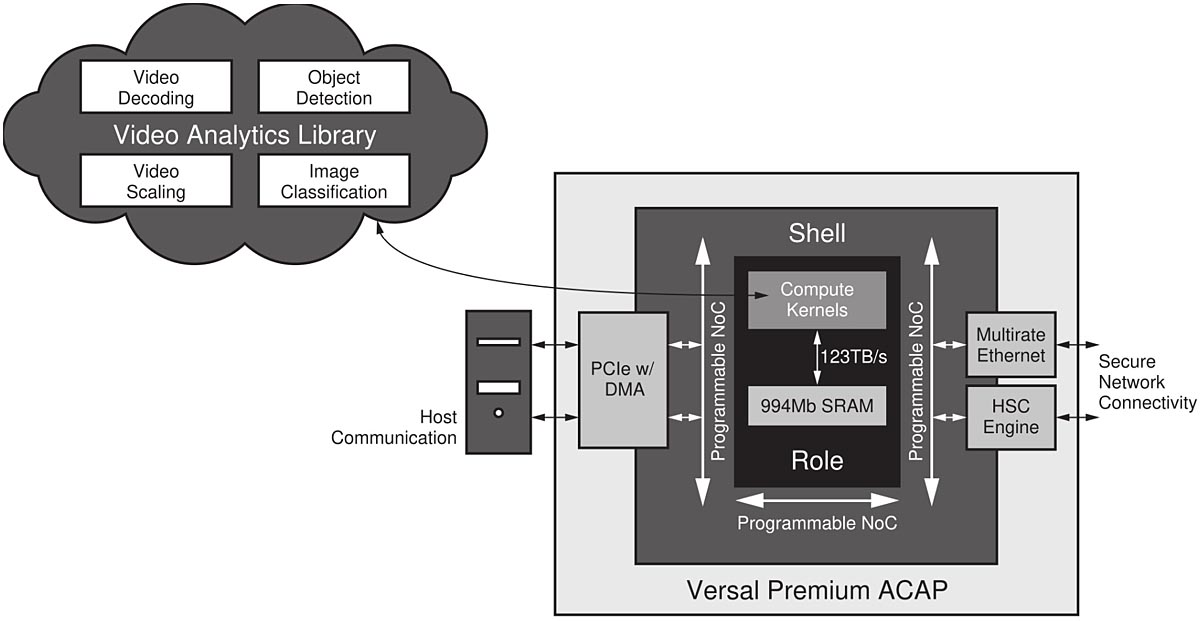
Skal- och rollarkitekturen hjälper designer att implementera avancerad smart handelsteknik snabbt och effektivt i Versal Premium ACAP. Enheterna kan hantera datadriven analys av videoinnehåll som kan hjälpa till att minska förluster och erbjuda automatiserad och användbar realtidsinformation och inblick i lagret samt möjligheten att skräddarsy kundupplevelser för att maximera försäljningen. Med Versal Premium ACAP är det möjligt att förvalta en videoanalyslösning på en enda plattform för identifiering, extrahering och klassificering av videometadata (figur 6).
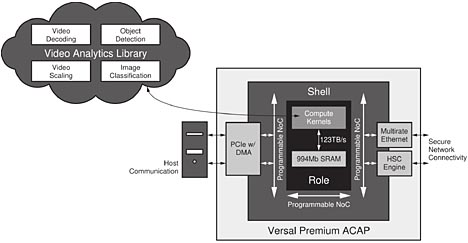
Figur 6. Accelerator för videoanalys inom smart handel (klicka för större bild)
Skalet ger färdiga anslutningsmöjligheter och kryptografi medan enhetens DSP-motorer och beräkningskärnor som kan programmeras via programvara hanterar objektdetektering och bildklassificering samt videokodning, -avkodning och -skalning. Upp till 1 Gbit av SRAM på chip finns i omedelbar anslutning till beräkningskärnorna, vilket ger upp till 123 Tbit/s i minnesbandbredd för AI-acceleration. Genom att eliminera minnesflaskhalsen och begränsningar i batchstorlek som hindrar GPU- och CPU-baserade arkitekturer kan en analyssccelerator fungera med upp till 13 000 bilder/sek för Resnet50.
Sammanfattning
I takt med att konsument- och affärsvärlden blir alltmer datacentrerad och kunderna förlitar sig på omedelbar leverans av tjänster, oavsett hur komplexa, beräkningsintensiva och bandbreddskrävande de är, erbjuder ACAP en kombination av effektiva, distribuerade heterogena beräkningsmotorer och snabb sammankoppling för att möta snabbt ökande prestandakrav. Genom att blanda hård IP, ett innovativt färdigt anslutningsskal och programmerbart logiksystem samt resurser som kan konfigureras med programvara ger dessa enheter inte bara högre prestanda, utan förenklar även designen och ger en framtidssäker flexibilitet.

Mike Thompson, Sr. Product Line Manager, Virtex UltraScale+ FPGA and Versal Premium ACAP på Xilinx
Filed under: FPGA, Utländsk Teknik





{kind=link}
{kind=link}