

Effektivare krypteringssystem
För att säkerställa säker och trygg överföring av data från källa till mål har kryptering kommit att bli en absolut nödvändig teknik för säkra program. Ahmed Majeed Khan och Asma Afzal, Khawar Khurshid från Cypress Semiconductor visar här hur man kan hantera krypteringen också i relativt små system.
De mest använda krypteringsteknikerna använder en deterministisk algoritm med en oföränderlig omvandling med datablock i fasta längder. Exempel på sådana tekniker omfattar bland annat AES (Advanced Encryption Standard), DES (Data Encryption Standard) IDEA (International Data Encryption Algorithm) och RC5.
Användning av ett sådant ”blockchiffer” begränsar genomflödet, databearbetningen och buffringskapaciteten hos maskinvaran eftersom krypteringen måste utföras innan nästa datamängd anländer. Ett stort antal industriella krypteringssystem stödjer datahastigheter över 200 Mbit/s, men maskinvaran som krävs för att uppnå detta, normalt en ASIC, är mycket dyr jämfört med en enkel mikrostyrenhet.
Även om det är möjligt att implementera kryptering på en enkel 8-bitars MCU med externt minne, exempelvis 8051, ligger den tid det tar att utföra kryptering i samma storleksordning som för en ASIC-lösning. I den här artikeln förklaras hur en SoC med programmerbar logik kan använda MCU-kärnan tillsammans med maskinvarufunktioner som universella digitala block (UDB:er) med direkt minnesåtkomst (DMA) för att effektivt implementera kryptering och förbättra systemets övergripande tidshantering.
AES är en av de mest använda blockchifferteknikerna som använder symmetrisk nyckelkryptografi. Vi använder AES-128 som ett exempel, som tillämpas på ett sjok av 16 byte (128 bitar) data som bearbetats med en 128-bitars chiffernyckel, för att visa vilka krav som ställs på en krypteringsapplikation och potentiella implementeringsalternativ. Med AES-128 ordnas indatabyte i form av att block innan bearbetningen startar, enligt vad som framgår av fig 1. I den här bilden är in0 första byte och in15 16:e och sista byte i indatablocket.
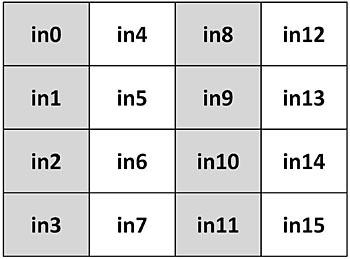
Fig 1. Indatabyte
Substitution av byte
Substitution av byte är den första operationen. I det här skedet byts varje byte i indatablocket ut mot en byte som väljs från den redan kända substitutionstabellen. Det valda värdet finns på den plats i tabellen som indatabytens båda halva byte pekar på, enligt fig 2. Substitution av en byte i rad och kolumn kan uttryckas som:![]()
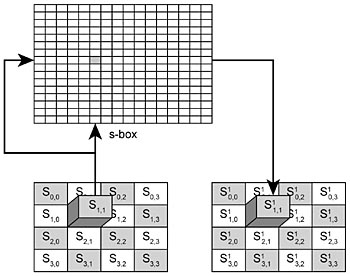
Fig 2. Substitution av byte
Substitutionstabellen är normalt hårdkodad i enheten (flash, SRAM etc). När processorn tilldelas uppgiften att byta ut byte hämtas indatabyte från programminnet och skickas som en adress till SRAM. SRAM returnerar den byte som finns på den platsen. Den här proceduren tar lång tid innan substitutionen av hela blocket är slutförd.
För att avlasta processorn från alla dessa operationer kan substitutionen ske samtidigt med hjälp av DMA:er så att processorn kan frigöras för andra uppgifter. Endast minnets käll- och måladress behöver tilldelas DMA och sedan kan all dataöverföring tas om hand. I stället för att skicka dessa värden till särskilda minnesplatser kan DMA dessutom överföra informationen direkt till UDB:erna för vidare bearbetning utan att processorn används.
Radskiftning
Nästa steg i AES är radskiftning. I det här steget förskjuts varje rad i det substituerade indatablocket en byte åt vänster. Den byte som ligger längst till vänster flyttas så att den hamnar längst till höger. I den första raden sker ingen skiftning. I den andra raden sker byteskiftningen en gång, i den tredje raden två gånger och i den fjärde raden tre gånger. Den här proceduren visas i fig 3.
Processorn kan bara utföra 8-bitars operationer och kan inte hantera hela blocket. Radskiftning innebär helt enkelt att en byte får en ny placering. Efter radskiftning får exempelvis byte den plats som tidigare innehades av. Därför kan DMA vara mycket effektivare när det gäller att hämta en byte från en adress och flytta den till en annan.
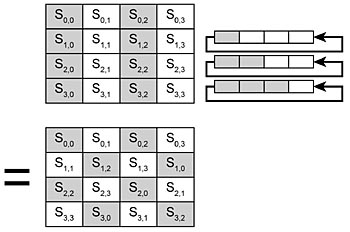
Fig 3. Radskiftning
Kolumnblandning
Efter radskiftning är kolumnblandning nästa steg. AES-kolumnblandning omfattar omvandling av datablocket så att hela kolumnen (4 byte) behandlas för att generera en byte. Omvandlingen är i grunden multiplikation i GF(28) med polynomet p(x)=x8+x4+x3+x+1. Matrisrepresentationen av kolumnblandning visas i fig 4.
Matematiskt genereras en byte A från a,b,c och d enligt följande ekvation:
A=02.a 03.b c d…(ii)
Implementering av multiplikation i maskinvara har alltid varit en utmaning, vilket är anledningen till varför den här ekvationen normalt sett inte implementeras i den här formen. Enligt boken Cryptography and Network Security kan multiplikation av ett värde med x (dvs med 02) implementeras som en 1-bitars vänsterskiftning följt av en villkorlig bitvis XOR med 0x1B(00011011),i om biten längst till vänster i det ursprungliga värdet (före skiftning) är 1. Enligt denna regel förenklas ekvationen ovan till: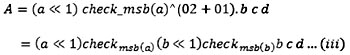
där ”check_msb” returnerar 0x1B om bytens MSB är 1 och returnerar 0x0 om MSB är 0. Den här enkla manipuleringen kan avsevärt reducera maskinvarans resursförbrukning vid kolumnblandning.

Fig 4. Kolumnblandning
En SoC med programmerbar arkitektur kan effektivt implementera den här processen i maskinvara. Med PSoC-arkitektur från Cypress kan Universal Digital Blocks (UDB) fungera som en idealisk kandidat för implementering av kolumnblandningsoperationen. Fig 5 visar UDB-arkitekturen från PSoC Technical Reference Manual (TRM).
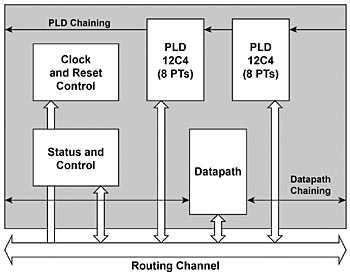
Fig 5. PSoC Universal Digital Blocks (UDB)
Man kan se att alla ovannämnda bytevisa operationer (skiftning bit för bit, XOR-operationer) kan utföras i en dataväg i en enda klockcykel. Innan vi går vidare till den faktiska implementeringen på UDB är det viktigt att förstå datavägens interna struktur.
En dataväg i UDB består av två 4 byte djupa FIFO:s, två dataregister, två ackumulatorregister och en 8 bitar bred ALU. Dessa maskinvaruresurser kan operera med hjälp av en tillståndsmaskin. Dessa 8 befintliga tillstånd kan konfigureras med hjälp av datavägskonfigurationsverktyget. Fig 6 från PSoC TRM visar datavägen.
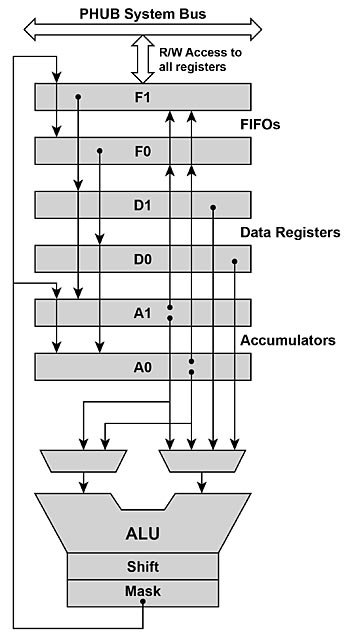
Fig 6. Dataväg i PSoC UDB:er
Fig 7 visar en tillståndsmaskin för implementering av ekvation-iii (kolumnblandningsoperation) med hjälp av UDB:er:
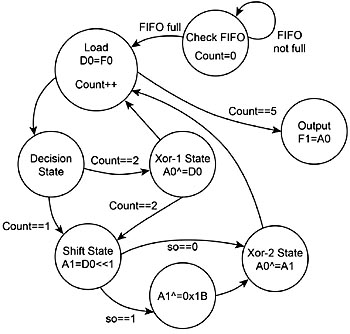
Fig 7. Tillståndsmaskin för kolumnblandning med hjälp av UDB:er
Av ekvation-iii kan man se att byten a, b, c och d krävs för att generera byte A. Här kan 4 byte djupa FIFO:s användas. Datavägen blir kvar i tillstånd Kontrollera FIFO tills alla 4 byte har tagits emot och indata-FIFO är fullt. Därefter flyttas datavägen till tillstånd Läs in där den hämtar en byte från FIFO:n och överför den till en ackumulator för vidare bearbetning. En räknare kan implementeras med ytterligare maskinvara (PLD) för att hålla reda på varje byte, eftersom varje byte hanteras på olika sätt. Eftersom byte a måste multipliceras med 2 (check_msb(a<<1)) skickas den av beslutstillståndet till tillstånd Skifta där den skiftas åt vänster bit för bit. Den utskiftade biten, (so i fig 7), avgör om den kräver XOR med 0x1B eller inte. På samma sätt stegar räknaren och tillståndsmaskinen opererar på varje byte enligt ekvation-iii. När räknaren når 5, vilket innebär att alla byte har lästs in och indata-FIFO nu är tom, kan resultatet läsas in i utdata-FIFO. Processorn kan hämta den blandade byten från utdata-FIFO när (utdata-FIFO inte tomt) avbrottet genereras. På så sätt kan överflyttning av kolumnblandning till UDB:er avlasta avsevärd bearbetning från processorn.
En hel kolumn (4 byte) kan genereras med ytterligare 3 liknande datavägar. Den enda skillnaden är räknarkontrollerna.
Nyckelexpansion och rundnyckeladdition
De sista stegen för AES är nyckelexpansion och nyckeladdition. I nyckelexpansion för AES-128 behandlas 128-bitars nyckeln så att den genererar elva 128-bitars rundnyckelblock (RK-block). XOR utförs på varje block, byte för byte, med datablocket. Nyckelexpansionsprocessen visas i fig 8. Varje RK genereras med användning av föregående RK. Den första RK:n genereras med hjälp av den faktiska 128-bitars nyckeln. Om RK(n-1) är föregående RK och RK(n) är aktuell RK genereras den första kolumnen för RK(n) av den första byte som ersätter den sista kolumnen i R4K(n-1) och skiftar den vertikalt cirkulärt uppåt. XOR utförs sedan på den kolumnen byte för byte med den första kolumnen för RK(n-1) för att ge den första kolumnen för RK(n). Den andra kolumnen för RK(n) är resultatet av XOR-utförandet byte för byte av den första kolumnen för RK(n) och den andra kolumnen för RK(n-1). På samma sätt är den tredje kolumnen för RK(n) resultatet av XOR-utförandet byte för byte av den andra kolumnen för RK(n) och den tredje kolumnen för RK(n-1). Den fjärde kolumnen för RK(n) genereras av XOR-utförandet byte för byte av den tredje kolumnen för RK(n) och den fjärde kolumnen för RK(n-1).
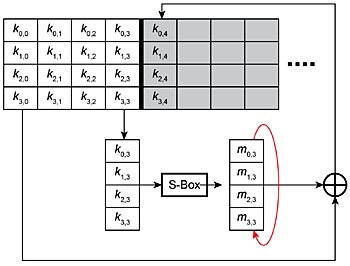
Fig 8. Nyckelexpansion
Nyckelexpansion och rundnyckeladdition kräver minne för lagring av föregående och aktuella 128-bitars nycklar samt för lagring av alla mellanliggande resultat. Även XOR-operationer på bytenivå krävs. DMA kan användas för att hämta byte från S-Box med referens från den 4:e kolumnen i 128-bitars nyckeln som är förlagrad i minnet och mata in en byte åt gången till UDB:erna. Med hjälp av en enkel datavägstillståndsmaskin kan UDB skifta den här kolumnen vertikalt. Utdatainformationen kan läsas antingen av processorn (CPU) eller av DMA. Den här kolumnen kan bli indata igen i en datavägs-FIFO tillsammans med den första kolumnen för en XOR-bearbetning byte för byte.
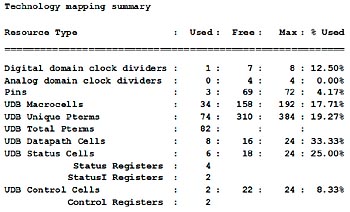
Fig 9. Resursförbrukning för kolumnblandningsoperationen
I fig 9 visas resursförbrukningen för den optimerade kolumnblandningsdesignen (avfrågningsbaserad) enligt beskrivning i tillståndsmaskinen ovan i fig 7.
Genom att använda de ytterligare maskinvaruresurserna i PSoC använder den här designen ungefär 34 % färre maskincykler än en vanlig processor-implementering. Introduktion av avbrott minskar belastningen på processorn ytterligare och genom att avlasta alla andra processer helt eller delvis till de externa maskinvaruresurserna blir resultatet en ännu snabbare och mer effektiv AES-implementering.
Ahmed Majeed Khan, Asma Afzal, Khawar Khurshid (Ph.D), Cypress Semiconductor
Filed under: Embedded




